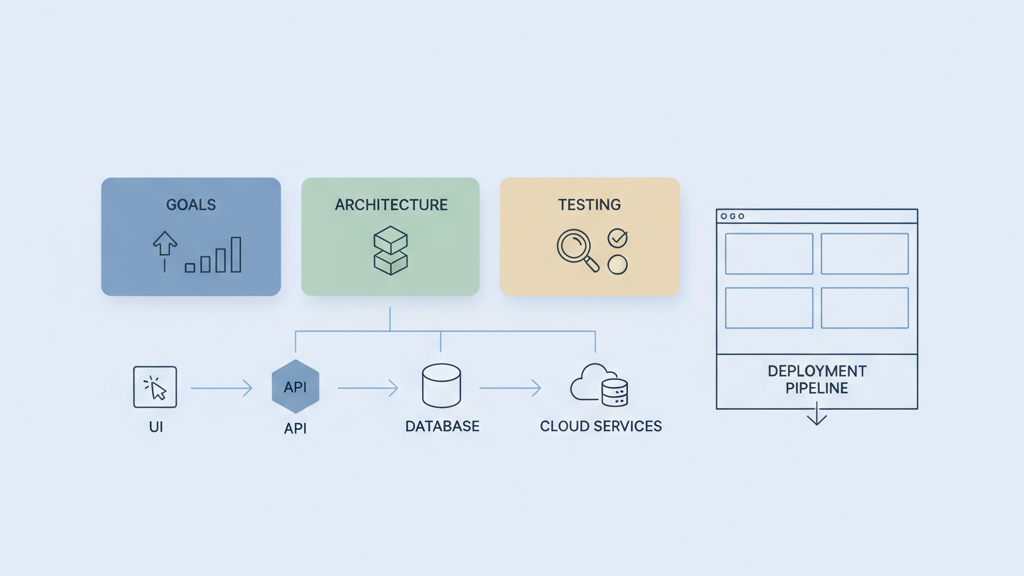
This guide covers steps to build a scalable prototype architecture overview for founders and product managers who need a clear path from idea to working prototype. I focus on pragmatic choices that reduce rework and keep costs predictable. Many startups miss early constraints and end up rewriting core systems. Read this to set measurable goals, pick the right tech patterns, and plan tests that show if the architecture will hold up under real growth. If you want a related deep dive, read How to Choose the Right Tech Stack for Your MVP Development.
Define Goals And Non Functional Requirements
Start by writing clear goals and non functional requirements that guide architecture choices. List target users, expected peak load, acceptable latency thresholds, and cost limits. Be concrete about success metrics so the team can measure progress. Include a short risk register for unknowns and for areas that need spikes or experiments. Many startups skip this step and then build systems that do not match real needs. Keep the scope narrow and mark what can be deferred to later phases. Use this document to make trade offs explicit and to align product and engineering on priorities. This process also helps decide where to accept technical debt and where to invest early for scalability. A focused goals page saves time and reduces wasted engineering effort. For a practical follow-up, see How To Set Product Metrics And KPIs For Startups That Scale.
- Write measurable performance targets
- List peak user scenarios
- Document cost constraints
- Create a small risk register
- Mark deferred features
Choose Patterns And Technology With Trade Offs
Pick proven architectural patterns that match your goals and team skills. Decide between monolith first or modular services based on expected independence of features. Consider serverless or container platforms for rapid iteration, but watch cold start and cost behavior. Evaluate managed services for databases and queues to reduce maintenance work. Trade offs matter more than novelty. A lightweight event driven approach may ease scaling later, but it adds complexity early. Prefer technologies your team can operate reliably. If you need rapid user feedback, choose a stack that supports fast deployments and simple rollbacks. Document why each choice was made and what will trigger a revisit. This keeps product velocity high while preserving options for future scaling. If you need implementation support, explore Software maintenance and scaling.
- Match patterns to goals not hype
- Prefer managed services for speed
- Balance complexity and visibility
- Choose tech the team can support
- Record decisions and revisit triggers
Define Data Models And API Contracts Early
Design clear data models and API contracts before building many components. Stable contracts let teams work in parallel and reduce integration friction. Use simple versioning patterns and backward compatible changes to avoid breaking consumers. Plan data ownership and boundaries so state is not duplicated across services without reason. Many teams underestimate the cost of migrating data and of divergent schemas. Create lightweight API specs and example payloads that cover error cases and edge flows. Automate contract tests as part of the pipeline so regressions are visible fast. This discipline saves refactors and prevents subtle runtime failures as load increases. Think through retention and archival to control storage costs over time. Teams moving from strategy to execution can review Backend API development.
- Create stable API contracts
- Version for backward compatibility
- Define data ownership boundaries
- Automate contract tests
- Plan retention and archival
Build Modular Components And Isolate Failure
Structure the prototype into clear modules that can be deployed independently when reasonable. Isolation reduces blast radius and helps observe where bottlenecks appear. Add simple health checks and graceful degradation strategies so non critical paths do not take down the whole system. Use queues or buffers to protect downstream services from spikes. Design observability into each module by emitting basic metrics and traces. Avoid coupling modules through shared databases when possible. Many founders under invest in isolation and face cascading failures later. Keep interfaces small and explicit. This modular approach makes it easier to replace or scale individual pieces without a heavy rewrite, and it improves the speed of troubleshooting when issues occur.
- Split into independent modules
- Add health checks and fallback paths
- Use queues to buffer spikes
- Emit basic metrics and traces
- Avoid shared database coupling
Plan Scalability Tests And Monitoring
Create tests that validate your assumptions about load and behavior. Start with lightweight load scripts that mimic real user flows. Increase complexity with concurrent users and background jobs to find contention points. Define success thresholds tied to your goals and watch for resource saturation. Build a monitoring dashboard that shows latency, error rates, throughput, and cost trends. Alert on business critical failures not on noise. Many teams only test functional behavior and only discover scaling issues in production. Schedule regular chaos style tests to confirm graceful degradation. Use test results to iterate architecture choices and to justify investments in optimization. Tracking cost per transaction is just as important as raw throughput. A related guide worth reviewing is Steps to Create a Lean Prototype for Startups That Validate Fast.
- Run realistic load tests
- Monitor latency and error rates
- Alert on business impact
- Perform chaos experiments
- Track cost per transaction
Automate Deployment And Manage Cost
Set up a simple CI pipeline that builds, tests, and deploys automatically to a staging environment. Keep deployments small and frequent to reduce risk. Use feature flags to control rollout and to test changes on a subset of users. Automate rollback paths so incidents are reversible quickly. Monitor cloud cost and set budgets early to avoid surprise bills. Many startups learn the cost lesson the hard way. Use autoscaling carefully and combine it with resource limits to prevent runaway spend. Schedule non critical tasks for off peak hours when possible. The right automation and cost checks keep the prototype usable for longer and make it easier to transition to a production ready system when the time comes.
- Implement CI with automated tests
- Use feature flags for rollouts
- Automate rollback procedures
- Set budgets and monitor spend
- Schedule heavy jobs off peak